Pure Python Machine Learning Module: Polynomial Tools Class
Find it on GitHub

Overview
I’ve been eager to get this tool released and reported here in preparation for several other blog posts. This tool mimics the Polynomial Features class of sklearn almost identically. The only way that it doesn’t match is in the order of the features. I got very close to matching the order, but I eventually had to admit to myself that I was being ridiculous to worry about this so much. There was also one benefit to this new class. It produces the polynomial features MUCH FASTER than sklearn’s class does. This shocked me. However, the speed of this class is not very important compared to the speed needs from other classes, so I don’t really think that this benefit is significant, but it was a pleasant surprise. Let’s get into the code right away, and then show that it’s working correctly.
REMINDER
This blog is not about some vain attempt to replace the AWESOME python modules for data science. It’s about understanding, among other things, how one might go about coding such tools without using scipy or numpy, so that we can someday gain greater insights, AND have a clue what to do, IF we need to advance or change the tools somehow.
CAUTION
If you are not familiar, or not strong, with what is meant by “polynomial features”, it might be best for you to start in the section further below named, “Checking Correct Functionality“. From there, we use a great tool called wxMaxima. I strongly encourage everyone to either use wxMaxima, OR use your favorite symbolic math solver, as you work through this post.
The Class Code
While there is a separate repo for the work of this blog, I have also added this class to the Machine Learning Module Repo on GitHub. That repo will grow with each new release associated with machine learning and it’s related tools.
ENCOURAGEMENT: When there is a section of code that you do not understand, what’s the best way to understand it and learn it? Break it down into the smallest inner most step(s), work to run and understand that part, and then add the next outer layer to it, and work to run and understand that, etc. Coding is best learned through small experimental tests (build a little, test it, and then troubleshooting is easier, repeat). Even when building your own code from scratch, start with the most essential single step, get that working, and then work outward to repeat that step for all cases if necessary. Master this technique, and you will be GLAD that you did.
Let’s step through the class one method at a time. IF you add all the code you see together in the order presented, you will have the entire class, BUT I recommend that you get the code, with comments, from GitHub. After reviewing the entire class, we’ll go over some tests of the class to show that it’s working properly. Finally, we’ll talk about upcoming work.
The code presented herein is NOT commented. The version of this code in the repo for this post and in the repo for the Machine Learning Pure Python module is commented heavily. Again, this class mimics sklearn’s PolynomialFeatures class to create various orders and types of polynomial variables from an initial set of supplied values for inputs or features being used in machine learning.
The first code block below covers the class instantiation (initialization for an instance of the class). The order of polynomials to be used can be set as high as you like, and the default is 2. If you only want the terms that represent interaction, you can set the interaction_only to True. This means that only those polynomial features with interaction, where the total power would add up to the given order, will be created for the set of polynomials, and the default value is false. The final parameter is include_bias and it has a default of True. This is the y intercept. The bias term is the one constant term in the final set of polynomial features. We’ll cover the __check_for_param_errors__ private method later. It simply makes sure that the parameters passed in are of the correct type.
class Poly_Features_Pure_Py:
def __init__(self, order=2,
interaction_only=False,
include_bias=True):
self.order = order
self.interaction_only = interaction_only
self.include_bias = include_bias
self.__check_for_param_errors__()
The next code block below contains the fit method. The fit method first makes sure that the input features are of the correct format. We’ll cover the __check_X_is_list_of_lists__ in more detail later. The number of vars is equal to the number of different features being passed in. We also initialize an array for the powers. This array will be used over and over and applied to the powers_lists array inside many recursive calls to __get_powers_lists__ when the conditions are appropriate. This method will be covered in great detail below, because it is the heart of this class. Once __get_powers_lists__ is complete, the final powers_lists is sorted. Finally, the powers_lists is modified according to the user’s parameter choices. We’ll cover the __modify_powers_lists__ private method further below.
def fit(self, X):
self.__check_X_is_list_of_lists__(X)
self.vars = len(X[0])
self.powers = [0]*self.vars
order = self.order
powers = self.powers
self.__get_powers_lists__(order=order,
var=1,
powers=powers,
powers_lists=set())
self.powers_lists.sort(reverse=True)
self.__modify_powers_lists__()
The next method is get_feature_names. The first section has an if block with 3 logical checks:
- If there are NO default names provided (this is the default case), then build a set of default names of the form x1, x2, … xn.
- If the user does provide feature names, but they don’t provide enough names, the code exits by raising a value error exception with a message informing them how many feature names must be provided.
- If the user has provided the correct number of feature names, but they are not all strings, the code exits by also raising a value error exception informing the user that the elements in the feature name list must all be strings.
The second section applies the powers from the powers_lists to the features names to give a human readable readout of the polynomial features containing algebraic variables in their various power combinations.
def get_feature_names(self, default_names=[]):
# Section 1: creates default names if not provided.
if len(default_names) == 0:
for i in range(self.vars):
default_names.append('x' + str(i))
elif len(default_names) != self.vars:
err_str = 'Provide exactly {} '
err_str += 'feature names.'
err_str = err_str.format(self.vars)
raise ValueError(err_str)
elif len(default_names) == self.vars:
check = [x for x in default_names if type(x) == str]
if len(check) != self.vars:
err_str = 'All feature names must '
err_str += 'be type string.'
raise ValueError(err_str)
# Section 2: Creates the features names based on the
# default base feature names.
feature_names = []
for powers in self.powers_lists:
prod = []
for i in range(len(default_names)):
if powers[i] == 0:
continue
elif powers[i] == 1:
val = default_names[i]
else:
val = default_names[i] + '^' + str(powers[i])
prod.append(val)
if prod == []:
prod = ['1']
feature_names.append(' '.join(prod))
return feature_names
The transform method first checks that X is of the correct format, because it could be a different X than was used in the fit method, but it must have the same number of features if so. It then applies all of the powers in the powers_lists array of arrays to the given feature values X. While it looks simple and elegant, I confess I had a lot of embarrassing brain farts along the way to reach that elegance.
def transform(self, X):
self.__check_X_is_list_of_lists__(X)
Xout = []
for row in X:
temp = []
for powers in self.powers_lists:
prod = 1
for i in range(len(row)):
prod *= row[i] ** powers[i]
temp.append(prod)
Xout.append(temp)
return Xout
The next method is fit_transform. This is simply for those frequent times that you want to both fit and transform your features into your needed polynomial format in one simple call.
def fit_transform(self, X):
self.__check_X_is_list_of_lists__(X)
self.fit(X)
return self.transform(X)
For whatever reason that you may want to check what the current parameters of your class instance are set to, you can call get_params to get a report of those current values.
def get_params(self):
tmp_dict = {'order':self.order,
'interaction_only':self.interaction_only,
'include_bias':self.include_bias}
print(tmp_dict)
Consequently, if your instance does NOT have the parameters set the way you like, and you don’t want to instantiate a new class, you can simply pass keyword argument pairs into the set_params method, and it will reset them for you. This method also makes sure each parameter is of the correct type. We’ll go over examples of how to set these kwargs in the example code, which is, of course, in the repo.
def set_params(self, **kwargs):
if 'order' in kwargs:
self.order = kwargs['order']
if 'interaction_only' in kwargs:
self.interaction_only = kwargs['interaction_only']
if 'include_bias' in kwargs:
self.include_bias = kwargs['include_bias']
self.__check_for_param_errors__()
Now we can cover those private functions that we kept glossing over above! The heart of this entire class resides in the __get_powers_lists__ method that is called recursively (when a function calls itself – sometimes getting this right is hard, but it’s very powerful!). Mastering a recursion like this one is not easy. There’s a lot going on, but you can do it. Push through! You might need to go study some links on recursive programming and come back here. I understand. Break it down into pieces and learn each piece. PLEASE follow the Encouragement that I provided above if you are seeking to understand this part fully. Mastering an understanding of this is not for the mathematically faint of heart.
While there are default values for each keyword parameter of this method, they are never used. I still wanted to define them for clarity. This method is called from fit, and the keyword argument pairs are initially set there. Once this is called, the for loop is entered, and the following things happen:
- the “var-1” index in powers is set to pow from the current value defined by the for loop (minus 1, because unlike most python sequences, I chose to have var start at 1 instead of 0);
- in the first if block, with powers_lists being a set (a set is a list with unique values in it – no repeats of any of the values in the list), the current powers array only gets added to the powers_lists as a tuple if the sum of the current powers array is less than or equal to the order;
- inside the second if block, var gets incremented by 1. If this incrementation exceeds the number of features (vars), the current recursion branch ends, and another branch is taken;
- as the calls go up and down the recursion tree, unique powers arrays that fulfill our conditions are added to the powers_lists array until the for loop at the top of the recursion tree is complete;
- covert the final powers_lists into a list of lists for operational convenience.
This entire procedure provides you with all the possible power combinations for your features.
def __get_powers_lists__(
self,
order=2,
var=1,
powers=[0,0],
powers_lists=set()):
for pow in range(order+1):
powers[var-1] = pow
if sum(powers) <= order:
powers_lists.add(tuple(powers))
if var < self.vars:
self.__get_powers_lists__(order=order,
var=var+1,
powers=powers,
powers_lists=powers_lists)
self.powers_lists = [list(x) for x in powers_lists]
For those of you that can get “mind numbed” by recursive calls, I have this to offer. Map out what you want to happen in a tree format. Think of ways to keep the tree from growing bigger than necessary. Code that and check that the state of variables are where you want them to be at each point in the operation. If you get something wrong, modify the plan and restart until you get it right. This usually does make my recursive programming go much more smoothly … when I remember to do it.
The last 3 private methods are short enough that we can cover them together. In __modify_powers_lists__, when we only want interactive terms in our polynomial features, it just so happens that these are all the terms whose total powers for each combined term add up to our order value. For example, if we had order = 3 and 3 features, the terms
x2^3, x1 x2^2, and x0 x2^2 would be included, because the total power of each term is 3, whereas the terms
x1 x2, x0 x2, x2, 3x1^2, x0 x1, x1, x0^2, and x0 wouldn’t be included, because the total power of each term does NOT add up to 3.
If we want the bias removed, we only remove the term in powers_lists that contains all zeros.
The __check_for_param_errors__ private method makes sure that all parameters are the correct value type.
The __check_X_is_list_of_lists__ private method ensures that X is in the correct format.
def __modify_powers_lists__(self):
if self.interaction_only == True:
self.powers_lists = [
x for x in self.powers_lists
if sum(x) == self.order]
if self.include_bias == False:
try:
self.powers_lists.remove([0]*self.vars)
except:
pass
def __check_for_param_errors__(self):
error_string = ''
if type(self.order) != int:
error_string += '"order" needs to be of type int. '
if type(self.interaction_only) != bool:
error_string += '"interaction_only" must be bool. '
if type(self.include_bias) != bool:
error_string += '"include_bias" must be bool. '
if error_string != '':
raise TypeError(error_string)
def __check_X_is_list_of_lists__(self, X):
error_string = 'X must be a list of lists.'
if type(X) != list:
raise TypeError(error_string)
if type(X[0]) != list:
raise TypeError(error_string)
Checking Correct Functionality
Let’s test a simple example first. I will be using both wxMaxima and sklearn’s Polynomial Features class for comparing to our new class. Why wxMaxima? It’s free, it works on any platform, you can use sudo apt-get install wxMaxima on linux, and did I happen to mention that it’s free? Let’s start with (x_0+x_1+1)^2. From wxMaxima we have
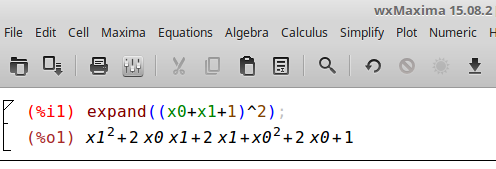
Putting the wxMaxima output in the format for our new class and the sklearn class yields, [1, x_0, x_0 x_1, x_0^2, x_1, x_1^2]. Sorted output from our class and sklearn’s class matches this output. I’ve left some helpful routines in the repo’s version of the class for testing.
Let’s next test (x_0+x_1+x_2+1)^3. From wxMaxima we have
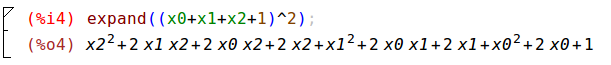
Putting the wxMaxima output in the format for our new class and the sklearn class yields,
[1, x_0, x_0 x_1, x_0 x_2, x_0^2, x_1, x_1 x_2, x_1^2, x_2, x_2^2].Sorted output from our class and sklearn’s class matches this output. I’ve left some helpful routines in the repo’s version of the class for testing.
For reasons of constructive and adequate laziness, let’s not use wxMaxima again, because it gets very tedious to modify it’s output for comparisons. Let’s next look at a large polynomial with 5 features and raised to order 3. The sorted outputs from our new class and sklearn’s class with all terms (i.e. NOT interaction_only terms) and bias provided both equal the following:
[1, x_0, x_0 x_1, x_0 x_1 x_2, x_0 x_1 x_3, x_0 x_1 x_4, x_0 x_1^2, x_0 x_2, x_0 x_2 x_3, x_0 x_2 x_4, x_0 x_2^2, x_0 x_3, x_0 x_3 x_4, x_0 x_3^2, \\x_0 x_4, x_0 x_4^2, x_0^2, x_0^2 x_1, x_0^2 x_2, x_0^2 x_3, x_0^2 x_4, x_0^3, x_1, x_1 x_2, x_1 x_2 x_3, x_1 x_2 x_4, x_1 x_2^2, x_1 x_3, x_1 x_3 x_4, \\x_1 x_3^2, x_1 x_4, x_1 x_4^2, x_1^2, x_1^2 x_2, x_1^2 x_3, x_1^2 x_4, x_1^3, x_2, x_2 x_3, x_2 x_3 x_4, x_2 x_3^2, x_2 x_4, x_2 x_4^2, x_2^2, \\x_2^2 x_3, x_2^2 x_4, x_2^3, x_3, x_3 x_4, x_3 x_4^2, x_3^2, x_3^2 x_4, x_3^3, x_4, x_4^2, x_4^3].Phew! That’s long! Let’s set the include_bias parameter in both classes to False, and make sure that the ‘1’ is dropped. They match! It’s the same as the output above, except that the ‘1’ is gone. One last test. Let’s set interaction_only parameter to True and still leave include_bias set to False. Here is the matching output from both classes:
[x_0 x_1 x_2, x_0 x_1 x_3, x_0 x_1 x_4, x_0 x_1^2, x_0 x_2 x_3, x_0 x_2 x_4, \\x_0 x_2^2, x_0 x_3 x_4, x_0 x_3^2, x_0 x_4^2, x_0^2 x_1, x_0^2 x_2, \\x_0^2 x_3, x_0^2 x_4, x_0^3, x_1 x_2 x_3, x_1 x_2 x_4, x_1 x_2^2, x_1 x_3 x_4, \\x_1 x_3^2, x_1 x_4^2, x_1^2 x_2, x_1^2 x_3, x_1^2 x_4, x_1^3, x_2 x_3 x_4, \\x_2 x_3^2, x_2 x_4^2, x_2^2 x_3, x_2^2 x_4, x_2^3, x_3 x_4^2, x_3^2 x_4, x_3^3, x_4^3].If you rerun these tests yourself, you will see that our pure python class is MUCH faster. I didn’t bother to test the speed difference, because unless you are processing a very large set of polynomial features, this is no big deal, but it was cool to come up with a pure python routine that was faster than an sklearn routine.
Closing
Now that we have this, we can test our pure python least squares routine using our output from our pure python polynomial features class. We will of course be able to use this for our future pure python machine learning classes. AND, with some modification, if you want that extra speed, you could modify this new class to work with numpy arrays too and use it with other sklearn machines.
I’ve already hinted at the next post – pure python least squares using the output of our polynomial features class as the new features input. After that, we should really cover some metrics for quality of fit on our one machine that we can apply to other machines too. After we have those in hand, we will move onto regularization and principle component analysis (PCA) and pure python methods by which we would obtain those eigen values and vectors. I’ve already begun some pre-work for those posts, so I hope to publish those soon.
Until next time …